
本文仅供有一定Elasticsearch、Logstash操作和运维基础的开发者参考
文中提到的的Elasticsearch集群和Logstash版本均为7.16.3
很多时候都会遇到,监控中心ES集群数据量太大,在日志或者监控数据的冷周期不使用删除而使用降低replica的方式导致磁盘空间挤爆、业务异常的问题
一般的解决方案就是不重要的数据删除,重要的冷数据转移到低配高磁盘空间的冷集群
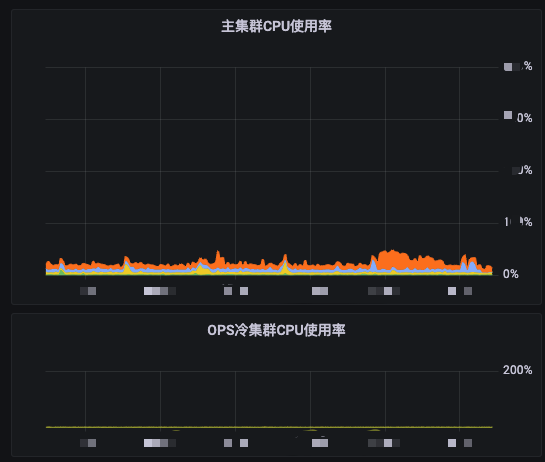
像这样,上半部分是主集群
下面是几乎用不到,仅作为平时用不到,偶尔回溯数据的冷集群
本文就简单介绍一种两集群间传输数据的方案
准备一台带有Logstash的OPS机器
安装方式不限,可以使用包管理工具安装或者二进制安装
创建迁移config
cd <location of your logstash installation>
vim conf.d/<some name your need>.conf
输入迁移所需的配置
input {
elasticsearch {
hosts => ["FROM-ES-IP:FROM-ES-PORT"]
user => "主集群有目标索引权限的用户名"
password => "主集群有目标索引权限的密码"
index => "需要同步的索引,可以使用占位符*"
scroll => "5m"
size => 1000
docinfo => true
}
}
output {
elasticsearch {
hosts => ["TARGET-ES-IP:TARGET-ES-PORT"]
user => "目标集群有创建索引权限的用户名"
password => "目标集群有创建索引权限的密码"
document_id => "%{[@metadata][_id]}"
index=>"%{[@metadata][_index]}"
}
}
需要关注的细节:
- input.elasticsearch.size: 每次滚动获取的数据量(hits)
- input.elasticsearch.docinfo: 每个同步的文档数据是否带上其元数据(info),如果不为true的话,可能会导致同步完之后冷集群的该索引只会有一条数据,其他数据均
deleted - output.elasticsearch.document_id: 与input的docinfo一样,创建的文档数据使用传入的id,这样可以与输入源保证每个文档数据的id一致
- output.elasticsearch.index: 使用传入的index的名字来创建
详情请参考光方文档:Elasticsearch input plugin
试试看
需要注意的是
一般的Logstash如果安装后你一直在运行,那么创建了conf文件后会自动的默认启动该pipeline,这是需要万分注意的!
我们配置传输23年一月10-19号的tengine log的数据
在主集群中查询:

在冷集群中查询:
curl "localhost:9200/_cat/indices/tengine_access-2023.01.1*?pretty&v&s=index"

没有任何数据~
然后启动同步!
日志输出↓

冷集群监控↓
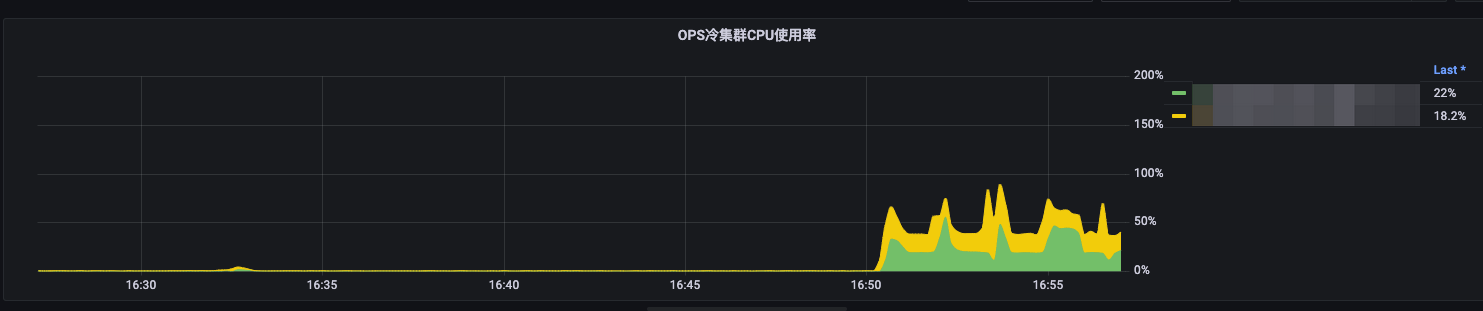
冷集群查询一下:
可以确认同步已经开始了
由于Elasticsearch的算法和机器网络限制,并不会占用太多的冷集群机器算力,所以同步时间也是与索引大小有关的,像本次demo索引的主分片就有约10GB数据
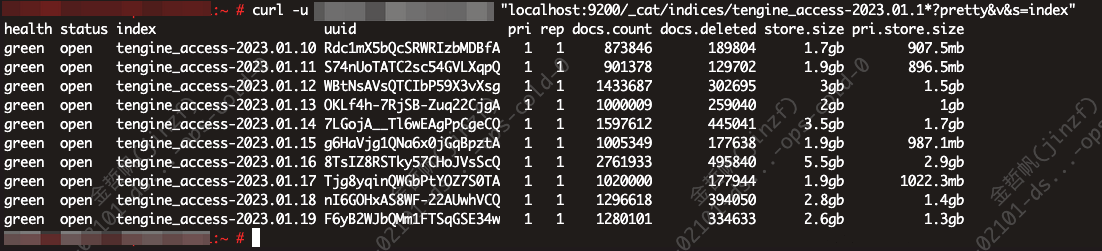
同步结束
文档数量与主集群查询时的一样
要注意⚠️的是:此时的Logstash进程不会停止,任何对于conf文件的修改都会使pipeline重启
减少分片
Logstash
冷集群的数据在同步时replica默认为1,但是其实我们对于这些数据的查询需求不高及其,所以只需要保留主分片就行了~
创建template文件:
/opt/logstash/config/replicas-one.json文件路径自行定义,只要Logstash进程可以访问到即可
{
"template": "tengine_access-*",
"settings": {
"number_of_replicas" : 0
}
}
该配置代表所有的tengine_access-*索引的replica均为0,也就是只保留主分片
在output部分加入
template => "/opt/logstash/config/replicas-one.json"
template_name => "replicas-one"
template_overwrite => false
也就是:
output {
elasticsearch {
hosts => ["XXX"]
user => "XXX"
password => "XXX"
document_id => "%{[@metadata][_id]}"
template => "/opt/logstash/config/replicas-one.json"
template_name => "replicas-one"
template_overwrite => false
index=>"%{[@metadata][_index]}"
}
}
要注意的是:template的设置仅初次会被在目标集群创建,后期如果修改了template内容,不会被应用于目标ES集群
如果想要每次template的修改都有效,需要将template_overwrite设置为true
详情请参考光方文档:Elasticsearch output plugin
HTTP API
使用http api就非常简单
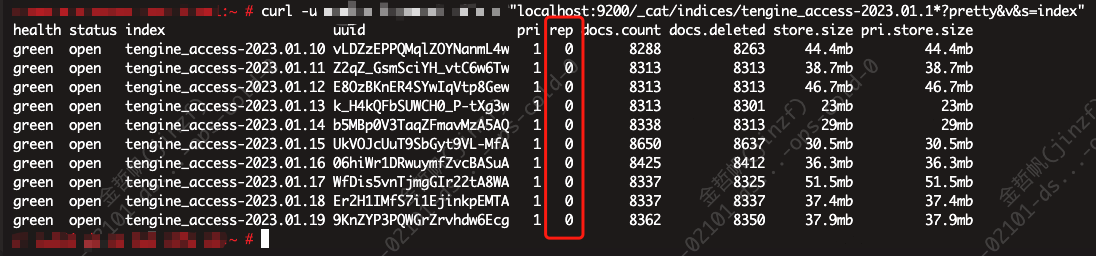
curl -X PUT "localhost:9200/tengine_access-2023.01.1*/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 0
}
}
' -u XXX:XXX
可以看到replica已变成为0!
两种设定replica方法各有利弊,请自行斟酌~

